介绍
顶顶通新一代FreeSWITCH智能客服接口,包含脚本解析引擎和话术编辑器2部分。
话术编辑器
话术编辑器是一个图形化的应用程序,通过图形化编辑话术流程,生成JSON文件。支持ASR流接口,支持多种打断方案,支持TTS,支持变量,支持真人录音,支持TTS和录音文件混合放音,支持正则表达式匹配,支持NLP接口,支持知识库,支持限制流程重复执行。
ASR支持
采用ASR流接口,可以实时得到识别结果进行匹配,可实现抢话,快速打断等高级功能。
TTS支持
支持变量,支持TTS和真人录音混合放音,支持TTS音量、语速、语调、发音人等参数设置,支持不同通话使用不同发音人等高级功能。
NLP支持
支持NLP接口,用户只需要专注于NLP接口实现,就可以实现高级的话术流程。
知识库支持
知识库和话术逻辑分离,让话术逻辑条理清晰,可以在话术节点触发知识库放音,知识库放音话可以返回节点播放一个返回音。知识库放音的时候同样可以进行ASR识别。
限制流程重复次数
可以防止机器人重复播放一个声音,或者流程进入死循环。
脚本解析引擎
脚本解析引擎是FreeSWTICH的内嵌模块,用来解析和执行话术编辑器生产的JSON文件。它非常高效和功能强大,没ESL接口或者RESTAPI接口的额外开销,不需要查询数据库。
标准化
JSON脚本,可以手动编辑,也可以第三方工具生成,使用标准格式,方便第三方编写话术编辑器。
高效
直接使用FreeSWITCH模块方式,没有协议对接开销,使用通道变量设置TTS变量,不需要查询数据库。
分布式
通过消息队列推送对话流程,方便大规模群集。
ASRPROXY
ASR和TTS接口程序程序实现阿里云和科大的ASR流接口对接。
测试
下载flowedit话术编辑器
下载地址:启动程序、
双击robotflow.exe,abc.json,ad.jsion,dtmf.json3个测试脚本选择一个打开测试。
sip软件模拟测试
下载一个SIP软件 http://www.ddrj.com/sipphone/index.html
SIP服务器:down.ddrj.com:11450
账户:121
分机密码联系微信:cdevelop 获取。
使用指南
全局配置
配置TTS,ASR和NLP
TTS配置
机器人引擎程序会根据配置生成 http://127.0.0.1:9989/tts?config=&voice=&volume=0&speechrate=0&pitchrate=0&engine=&text=%E4%BD%A0%E5%A5%BD%E8%BF%99%E9%87%8C%E6%98%AF%E9%A1%B6%E9%A1%B6%E9%80%9A%E8%BD%AF%E4%BB%B6 这样的路径去播放声音,voice和text使用utf8字符编码,然后进行url编码。用户可以直接实现TTS服务,也可以使用ASRPROXY提供的tts服务。
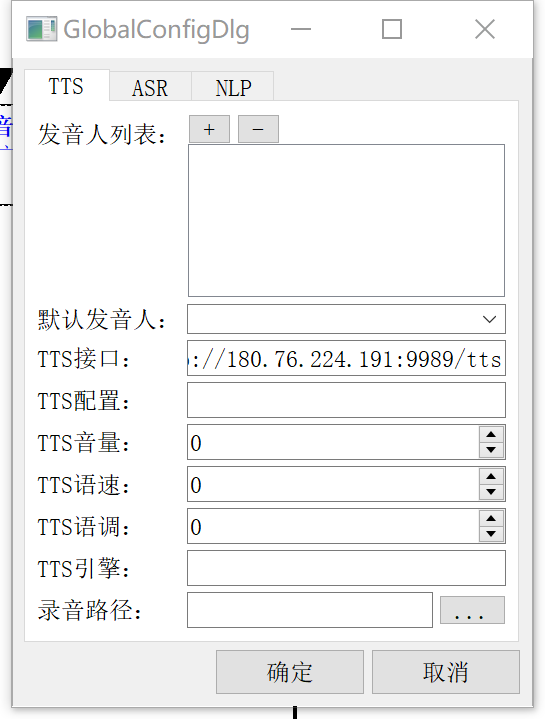
发音人列表:可以配置多个发音人,每个电话循环使用发音人,避免每个电话都是同样的声音。
- 阿里云 https://help.aliyun.com/document_detail/84435.html 这个页面看voice参数值。
- 科大讯飞 https://console.xfyun.cn/services/tts 这个页面发音人授权管理看参数(vcn/voice_name)的值。以下及几个基础发音人,特色发音人联系科大购买。
- 讯飞小燕(xiaoyan)
- 讯飞许久(aisjiuxu)
- 讯飞小萍(aisxping)
- 讯飞小婧(aisjinger)
- 讯飞许小宝(aisbabyxu)
- 百度
- 度小宇=1
- 度小美=0
- 度逍遥(基础)=3
- 度丫丫=4
- 下面几个发音人都需要购买的
- 度逍遥(精品)=5003
- 度小鹿=5118
- 度博文=106
- 度小童=110
- 度小萌=111
- 度米朵=103
- 度小娇=5
- 华为云 https://support.huaweicloud.com/api-sis/sis_03_0111.html#sis_03_0111__table16841320278 这个页面看具体发音人列表
默认发音人:如果配置了默认发音人,就不会使用循环使用发音人列表里面的发音人。
- TTS接口:如果使用ASRPROXY,配置 http://127..0.0.1:0089/tts 这个地址
- TTS配置:ASRPROXY可以配置多个不同的TTS服务和KEY,通过这个配置来控制使用具体的TTS服务。
- 录音路径: 不是TTS文件的缓存录音路径,是真人录音文件的存放目录。
- 音量语速语调:都是0-100之间 0默认 100最大。注意比如官方的参数是 -500到500,比如90转换成官方参数算法是:90 * 10 - 500 = 400, 比如官方参数 200转换成接口参数的算法是:(200+500)/10=70
- 引擎
- 阿里云
0 统计参数合成: 基于统计参数的语音合成,优点是能适应的韵律特征的范围较宽,合成器比特率低,资源占用小,性能高,音质适中1 波形拼接合成: 基于高质量音库提取学习合成,资源占用相对较高,音质较好,更加贴近真实发音,但没有参数合成稳定
- 阿里云
ASR配置
设置默认ASR参数,如果流程节点单独设置了ASR参数,就会覆盖全局设置。
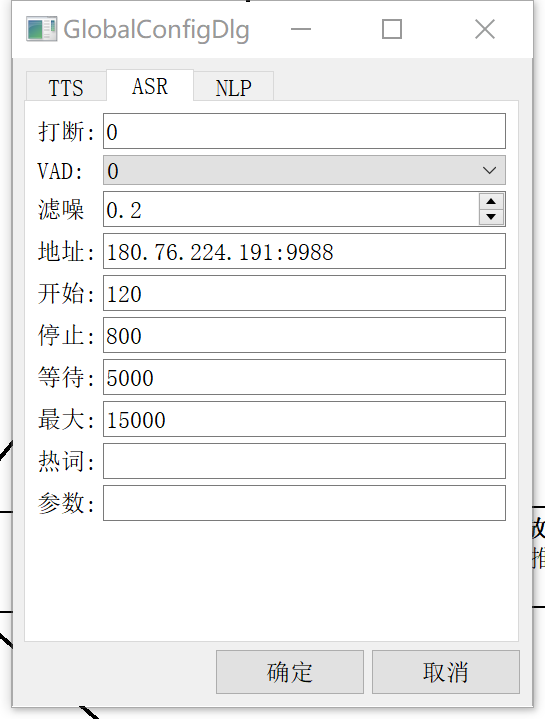
模式:【mode】0:不启动ASR识别 1:放音的同时开启ASR识别; 2:放音完成之后才开启ASR识别。
打断模式:【interrupt】 :
- 0:关键词打断; 【关键词打断的可选功能,可以组合使用,比如要使用128和256,就设置384。】
- 16: 放音结束后识别到一句话就停止等待(执行完成)。
- 32 : 放音时识别到一句话,放音完成后就不等待(执行完成)(隐含16)。
- 64:放音时检测到声音就暂停放音(只暂停放音,识别结果未匹配到关键词,还会恢复放音)。
- 128 : 放音时如果有被禁止打断(disablebreak)过滤的识别结果,放音完成时,如果用户不在说话中,重新尝试关键词匹配(识别结果前面会加一个P)。
- 256 : 放音时如果有未匹配的识别结果,放音完成时,如果用户不在说话中,再次尝试关键词匹配(识别结果前面会加一个P)。
- 512:dtmf按键打断(默认只有符合按键终止符才会停止放音,如果需要不符合按键终止符也停止放音,就需要设置这个参数)
- 1:检测到声音就打断;
- 2:ASR识别到文字就打断;
- 3:ASR识别到一句话就打断。
- 0:关键词打断; 【关键词打断的可选功能,可以组合使用,比如要使用128和256,就设置384。】
vad模式:【vad_mode 】
- 0:使用本地VAD检测说话开始和结束
- 1:等待ASR反馈说开始和结束(需要ASR支持)
- 2:使用本地VAD检测检测说话开始,等待ASR反馈说话结束。
滤噪:【vad_filter】 设置大于0.8 就会启用神经网络的噪音过滤算法,小于0.8根据历史音量过滤噪音,如果需要防止噪音打断和噪音错误识别成关键词建议设置0.8,否则设置0.2。
- 地址:【asrproxy_addr】asr代理地址。
- 开始:【vad_min_active_time_ms】说话时间大于这个值才开始提交ASR。
- 停止:【vad_max_end_silence_time_ms】静音时间大于这个值认为说话停止。
- 等待:【wait_speech_timeout_ms】放音完成后等待用户说话的等待时间。
- 最大:【max_speech_time_ms】最大说话时间,说话时间超过这个值就停止ASR。
- 热词:【hot_word】ASR热词。
- 参数:【asr_params】ASR参数。例如:
{\"group\":\"default\"},控制asrproxy使用那个asr配置组去识别。 - 录音:【record_mode】录音方式。0:不录音,1:检测到声音开始录音,2:全部录音。
- 路径:【record_template】录音路径模板。如果不是绝对路径,会把这个路径追加到FreeSWITCH的recordings后面。支持变量,比如日期 ${strftime(%Y-%m-%d)}。最后一个录音文件路径会保存到变量 ${cti_asr_last_record_filename}
NLP配置
配置NLP接口地址和同义词组。

- 接口地址:NLP接口地址。
- 同义词组:把相同一样的词可以放到一个组里,配置流程的时候,可以直接选择关键词组。
意向配置
可以根据意向转接到分机或者通知到http接口。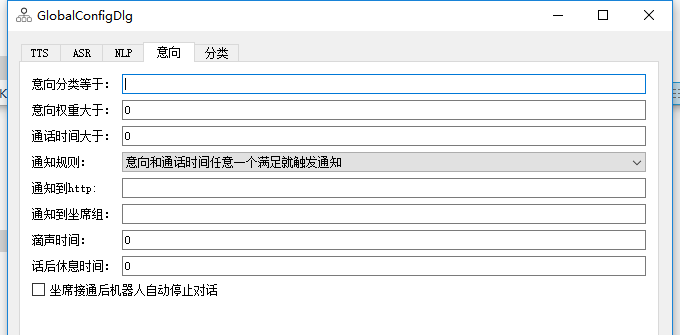
intention_label 意向分类等于这个值这个值触发意向通知,多个意向用逗号隔开。
intention_threshold 意向权重大于这个值触发意向通知
calltime_threshold 通话时间大于多少秒触发意向通知,单位秒。
notify_condition 通知规则(0:意向(意向权重或者意向分类)和通话时间任意一个满足就触发通知,1:意向(意向权重或者意向分类只需要一个满足)和通话时间2个同时满足才触发通知,2:根据分类设置实时计算意向)
notify_http 通知到http接口地址
notify_linegroup 通知到坐席组,就是线路组。 也可以通过通道变量 cti_triggernotify_linegroup 设置。
human_answer_stop_robot 0:坐席接通后进入监听模式,按DTMF*才进入通话模式 ,1:坐席接通后机器人自动停止对话 。
beep_time 坐席接通时的滴声时间,单位毫秒。
rest_time 坐席接完一个电话后的休息时间,单位毫秒。
触发意向的流程信息会存储在 通道变量 trigger_flow里面格式话术名字[触发节点ID]。
如果需要把触发意向的流程信息通过sip头通知到客户端,可以在进入机器人的拨号方案里面配置
- export nolocal:origination_nested_vars=true
- export nolocal:sip_h_trigger_flow=\${cti_robot_manua_trigger_flow}
如果有执行伴随转接,会设置以下通道变量
- cti_robot_manua_trigger_flow 触发转人工的流程信息
- cti_robot_manual_linegroup 转人工的线路组
- cti_robot_manual_linename 转人工的线路名
- cti_robot_manual_state 转人工最终状态
- origiante 呼叫了,但是没接通
- eavesdrop 监听了,但是没接管
- bridge 人工接管了
分类配置
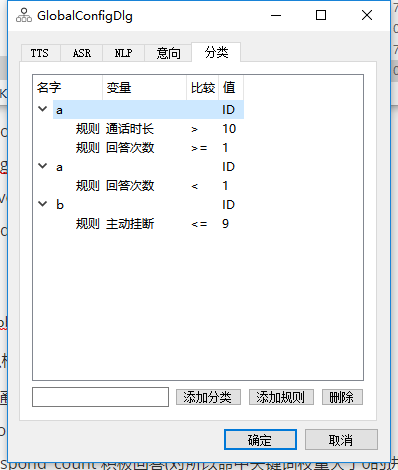
通话结束后可以根据 以下变量中的一个或者多个来进行分类。
- talk_time 通话时长
- respond_count 回答次数
- positive_respond_count 积极回答(对所以命中关键词权重大于0的进行求和)。举例:比如肯定关键词权重都设置1,那么积极回答的值就是肯定回答了多少次。
- passive_respond_count 消极回答(对所有命中关键词权重小于0的进行求和然后取绝对值)。举例:比如否定关键词权重都设置-1,那么消极回答的值就是否定回答了多少次。
- intentional_count 有意向节点(对所有执行节点意向大于0的进行求和)。举例:比如有意向的节点意向都设置1,那么这个值就是执行了多少个有意向的节点。
- unintentional_count 无意向节点(对所有执行节点意向小于0的进行求和然后取绝对值)。举例:比如无意向的节点意向都设置-1,那么这个值就是执行了多少个无意向的节点。
- trigger_global_flow 触发全局流程次数
- trigger_kb 触发知识库次数
- proactively_hangup 机器人主动挂断设置为1,否则设置为0
知识库
把常见问题的回复预先定义好,可以通过关键词或者NLP触发知识库放音

- 分类:可以设置很多不同的分类方便和流程结点关联
- 关键词(keywords):支持正则表达式,识别到关键词,就触发机器人放音
- 放音(playbacks):支持TTS和文件放音支持变量。
- 重复(repetition):可以防止多次重复触发。
- 意向(potential):意向权重,正数就是有意向节点,负数就是无意向节点,强制设置意向值前面加个等于号,比如=5意向强制设置为5。也可以直接设置意向分类比如A、B、C等。
- 忽略流程放音(ignorereturnplayback) 1:忽略,其他值不忽略。知识库放音完成后默认自动播放流程放音,可以通过这个配置只播放知识库放音,不播放流程放音。
- 切换流程(switchflow) 可以通过知识库切换到子流程,子流程执行完成可以回到主流程就行执行。
- 流程ID 切换到指定流程
- hangup 挂断通话
- text:前缀 切换到当前流程的文本输入匹配的子流程
- dtmf:前缀 切换到当前流程的DTMF输入匹配的子流程
- complete:前缀 切换到当前流程的完成输入匹配的子流程
- return 返回源流程(只有从全局流程进入到知识库才有源流程。)
- 触发通知(triggernotify) 执行到这个知识库就强制触发意向通知(通知到坐席或者http,在配置意向里面设置)。如果需要通知到指定的线路组组,可以添加属性triggernotify_linegroup(线路组),human_answer_stop_robot(接通就停止机器人流程),覆盖全局设置设置。
- 去除前缀 语音识别结果和关键词匹配前,先去除前缀F|S|D|P等。
流程编辑
通过拖拉方式配置话术流程。
全局流程
需要多处重复执行的流程,可以单独配置一个全局流程
时间限制
只匹配通话的前多少毫秒的识别结果,不设置或者0无限制,单位毫秒
按次限制
只匹配前多少次的识别结果,不设置或者0无限制,一句话算一次,禁止打断时候说话不算
忽略禁止打断
就算配置了禁止打断,也尝试匹配这个全局流程,典型的用法开场白设置了静止打断,但是要挂断语音信箱应答的通话。
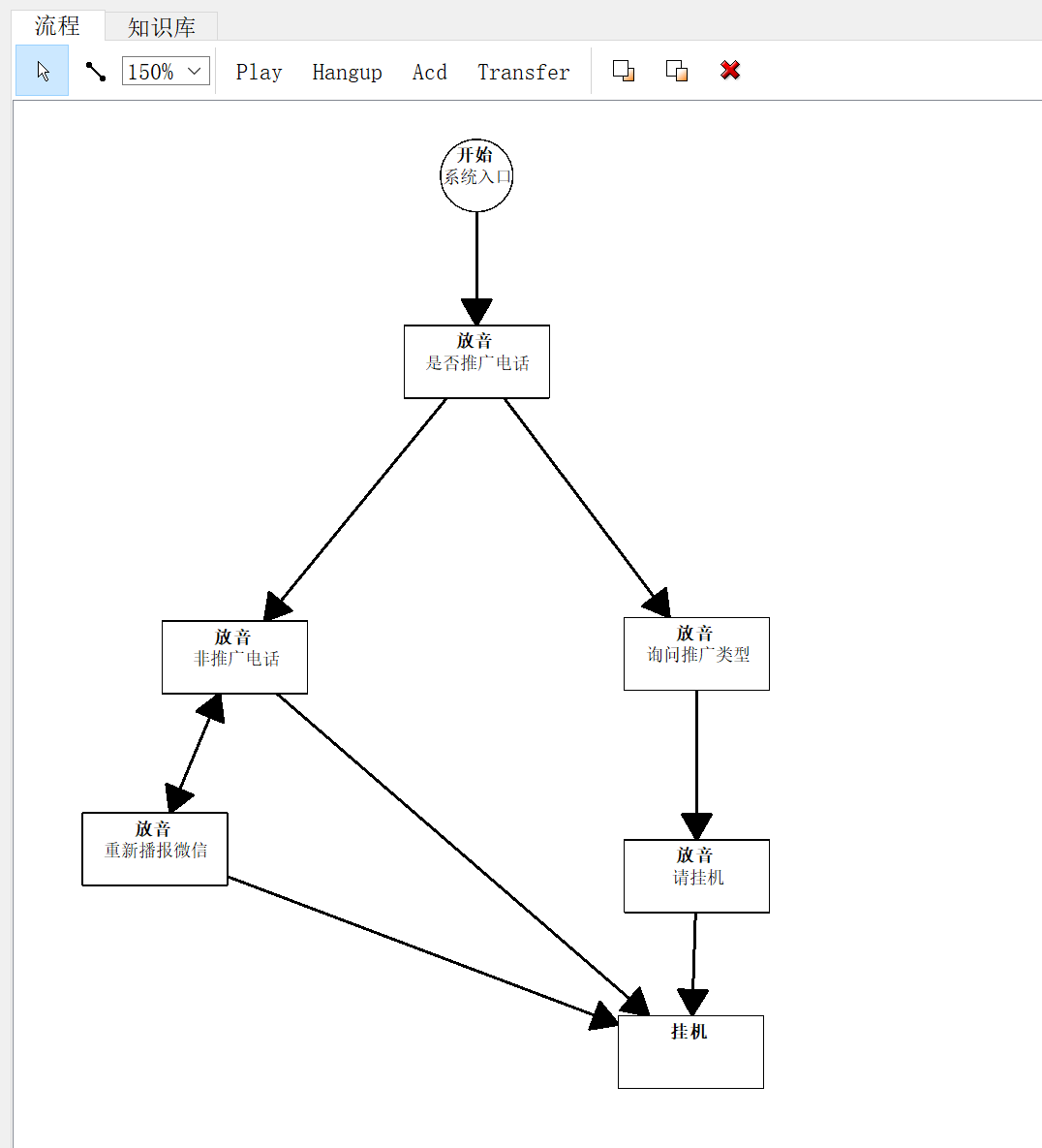
流程节点
通用
描述:介绍流程的用处
ID: 唯一ID
意向: 意向权重,正数就是有意向节点,负数就是无意向节点,强制设置意向值前面加个等于号,比如=5意向强制设置为5。也可以直接设置意向分类比如A、B、C等。
触发通知:执行到这个节点就强制触发意向通知(通知到坐席或者http,在配置意向里面设置)。如果需要通知到指定的线路组组,可以添加属性triggernotify_linegroup(线路组),human_answer_stop_robot(接通就停止机器人流程),覆盖全局设置设置。
重复限制:动作最大执行次数,可防止流程进入死循环,不设置或者0,不限制,比如设置1,就是限制只能执行1次
全局流程
- 时间限制(timelimit): 只匹配通话的前多少毫秒的识别结果,不设置或者0无限制,单位毫秒,就电话接通前面多少秒说话,才可以匹配到这个全局流程。
- 按次限制(asrcountlimit):只匹配前多少次的识别结果,不设置或者0无限制,一句话算一次,禁止打断时候说话不算,就电话接通前面多少次说话,才可以匹配到这个全局流程。
- 忽略禁止打断(ignoredisablebreak):就算配置了禁止打断,也尝试匹配这个全局流程
- 模拟知识库(iskb): 命中统计为触发知识库
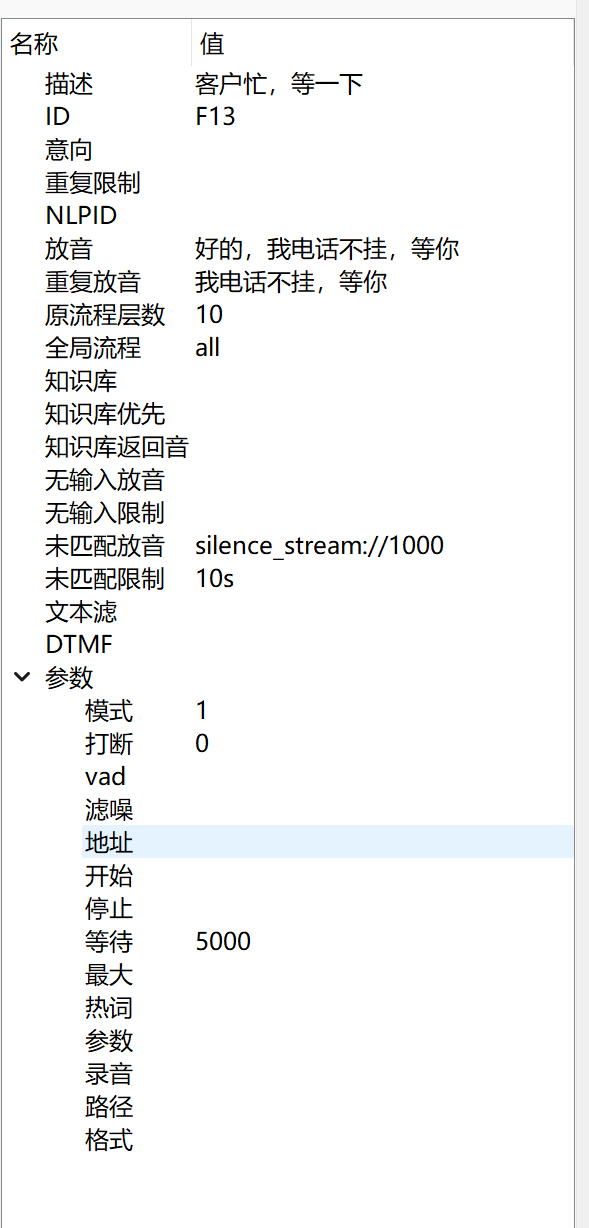
放音
- NLPID(nlpid):NLP ID,配置了这个值才会把输入事件提交给NLP接口处理
- 放音(playbacks):机器人播放的声音文件
- 重复放音(replaybacks):第二次进入(比如其他流程返回)机器人播放的声音文件,如果不设置,会使用“放音”设置的参数。如果没配置知识库返回音,知识库返回也会播放这个声音。
- 第三次放音(thirdplaybacks):第三次或者更多次进入(比如其他流程返回)机器人播放的声音文件,如果不设置,会使用“重复放音”设置的参数。知识库返回会忽略这个配置
- 更多次放音(fourplaybacks):第四次或者以后进入(比如其他流程返回)机器人播放的声音文件,如果不设置,会使用“重复放音”设置的参数。知识库返回会忽略这个配置。
- 原流程层数(sourceflowdepth):输入和原流程(通过知识库切换流程或者全局流程进入时的流程)的子流程条件进行匹配。0:不关联原流程,大于0:关联原流程的层数。用法见下图。注意不会匹配原流程的any分支,但是可以匹配.*分支
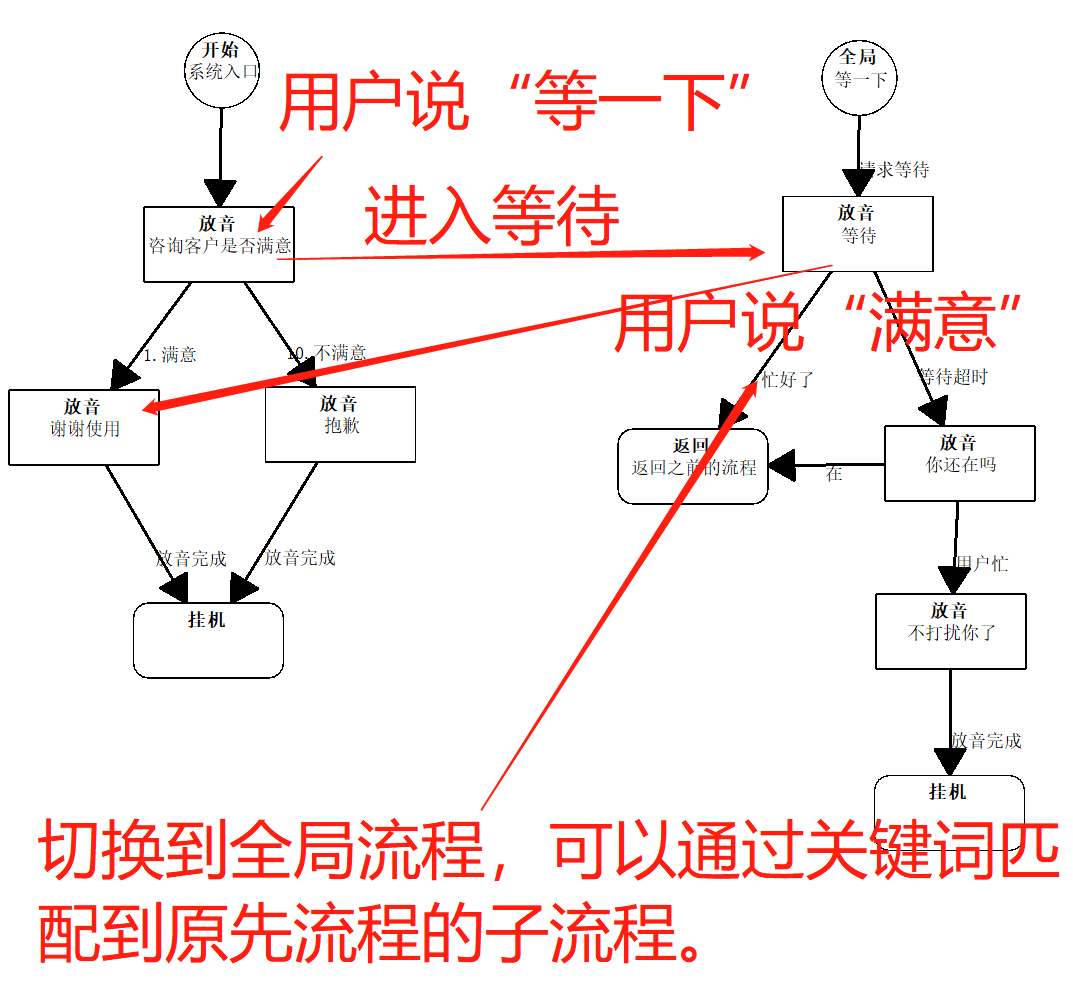
- 全局流程(globalflow): 关联的知全局流程,可以设置多个,all:关联所有全局流程。为了防止死循环,全局流程的子流程,会自动排除所在的全局流程,即不会关联所在的全局流程。
- 知识库优先(kb_priority):0:子流程优先,1:知识库优先。默认是先匹配子流程关键词,然后匹配知识库关键词,如果设置了知识库优先,就会先匹配知识库关键词,然后再匹配子流程关键词。
- 知识库(kb):设置关联的知识库
- 知识库返回音(kbplaybacks):播放完知识库回答后播放的声音,如果没配置会播放重复放音
- 流程返回音(returnplaybacks):全局流程返回后播放的声音,如果没配置会播放知识库返回音
- 返回切换流程(kbswitchflow):触发知识库或者全局流程返回后,直接执行切换流程(不播放知识库返回音),top:返回到最顶级流程,return:返回到上一级流程,也可以指定流ID。其他参数和return动作的返回值一样”),注意不会多次执行,也就是kbswitchflow切换到目标流程后,不会继续执行目标流程的kbswitchflow
- 无输入放音(timeoutplaybacks):DTMF按键超时或者未检测到用户说话(ASR没识别到文字)机器人播放的声音文件,优先级高于(ANY),如果无输入次数超过限制,则执行ANY流程。如果没设置无输入放音但是设置了未匹配放音,则执行未匹配放音。
- 无输入追加放音(timeoutaddplayback):无输入放音之后是否播放默认放音(如果配置了重复放音,就是播放重复放音,如果没配置重复放音,就是使用放音配置)。
- 无输入限制(timeoutrepetition):无输入放音最大连续执行次数,如果最后一个字符是s,表示使用时间限制代替次数限制,单位秒。比如10s,表示10秒之内TIMEOUT()输入,都执行无输入放音,10秒之后则执行ANY流程。
- 未匹配放音(mismatchplaybacks):未匹配到关键词播放的声音
- 未匹配追加放音(mismatchaddplayback):未匹配放音之后是否播放默认放音(如果配置了重复放音,就是播放重复放音,如果没配置重复放音,就是使用放音配置)。
- 未匹配限制(mismatchrepetition):未匹配关键词最大重复播放未匹配声音的次数,超过次数会走ANY流程。
- dtmf(filter.dtmf): DTMF终止符,any:任意字符,none:无终止符,max=最大输入DTMF个数,比如max=16,只有设置了DTMF终止符,才会处理DTMF输入,如果要放音的时候忽略按键,加上
noplay,前缀。(DTMF就是电话按键的别称) - 噪音规则(noiserule):ASR会把噪音错误的识别成文字,可以通过正则表达式,把一些识别结果判断为噪音过滤掉。
- 禁止打断(disablebreak):控制是否允许打断,-1:放音的时候都不允许打断。0:任何时候都允许打断,大于0:放音前多少毫秒内禁止打断。 【禁止打断时说话会执行ASR识别,但是不会执行关键词匹配逻辑,如果需要放音时说话不执行ASR识别,可以直接修改ASR模式。】
- 忽略禁止打断(ignoredisablebreak):设置知识库返回或者全局返回时忽略禁止打断,0:禁用 1:知识库返回时 2:全局流程返回时 3:知识库和全局流程返回时
- 允许抢话(quickresponse):需要ASR流接口能实时返回识别结果才支持抢话,就是不等用户说完,就开始匹配关键词,让机器人更快的回答。
- 模式:【mode】0:不启动ASR识别 1:放音的同时开启ASR识别; 2:放音完成之后才开启ASR识别。
- ASR参数可以覆盖全局配置的默认ASR设置
转移
- 分机:extension:拨号方案目的的。
- 拨号方案:dialplan:拨号方案类型,默认XML。
- 上下文:拨号方案上下文。类如public,default
直接转接到手机或者分机
- 通过 bridge 桥接
fs发起一个新呼叫,然后把2个呼叫绑定,如果呼叫失败,不能返回机器人。如果需要返回机器人,需要用伴随转接,或者ACD排队转接。
拨号方案填写 inline,转手机分机填写bridge:linegroup/外呼线路组/手机号码,转坐席分机填写bridge:user/分机号,转线路组分机填写linegroup/坐席线路组 - 通过 SIP 信令 REFER 转接,直接通知对方去转接
拨号方案填写 inline,分机填写 deflect:sip:转接号码@对方Ip
返回
- 重放知识库(kbreplay): 如果上一个放音包含知识库放音,返回时是否重放知识库。通过知识库切换到返回节点的不会生效,只有通过关键词切换到返回节点的才会生效。典型的用法时播放知识库时,客户要求重放一次知识库声音。
- 忽略源流程放音(blockplay):返回源流程后,不播放源流程的放音
- 放音:这个放音会和跳转后节点的放音连接起来,如果跳转后的节点不支持放音,那么这个放音不会生效。
- 返回值:
- 空或者return:返回到调用流程;
- 流程ID:返回到指定流程(如果找不到流程,则挂机);
- top: 返回到第一次切换流程时的当前流程(也就是最初的流程),比如主流程进入到了全局流程,这样的才是流程切换。进入子流程不算流程切换。;
- “text:”:前缀匹配调用流程的文本输入;
- “dtmf:”:前缀匹配调用流程的DTMF输入;
- “complete:”:前缀匹配调用流程的完成输入。(如果通过输入匹配不到子流程,则返回调用流程)
排队
- 名字:要进入的排队名字。
- 等待:最大等待时间,单位秒。默认不限制。不等待:nowait
- 优先级: 总的3个优先级, 0:低优先级 1:中(默认) 2:高优先级别。
条件判断
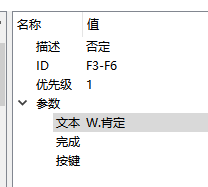
优先级(priority):匹配的顺序,从高到低匹配。
关键词权重(keywordweight):积极关键词(比如肯定)设置为正数;消极关键词(比如否定)设置为负数。中性关键词设置为0或者不设置。
去除前缀 按键或者语音识别结果和关键词匹配前,先去除前缀F|S|D|P等。
文本(condition.text): 说话会触发这个事件,[asr识别结果,支持正则表达书,ANY表示匹配任意文本,如果配置了未匹配放音,只有未匹配次数超过了限制,才执行ANY。
- 前缀F 识别完成
- 前缀E 系统错误
- 前缀S 识别中,需要开启允许抢话才有实时输入
- 前缀P 放音时的识别结果(打断模式128和256时放音时候说话才触发)
完成(condition.complete):流程节点执行完成会触发这个事件,完成原因格式BREAK|DONE|TIMEOUT|ERROR|HANGUP,ANY匹配任意原因,如果配置了未匹配放音,只有未匹配次数超过了限制,才执行ANY,为了意外情况,建议每个节点,都添加一个any子节点。
- TIMEOUT 放音完成后,等待【wait_speech_timeout_ms】事件内没有按键或者说话,或者最大说话时间到了,还没停止说话。TIMEOUT(F:放音时候的识别内容S:超过最大说话时间了)。如果没检测到声音就是TIMEOUT()。
- DONE 按键符合终止条件,或者说话停止了,但是 DTMF和文本都没匹配上子流程。
- ERROR 动作执行遇到错误。比如放音文件不存在
- BREAK 动作给外部打断了。
- HANGUP 通话挂断了
按键(condition.dtmf):必须配置了DTMF终止符,电话按键才会触发这个事件,输入格式[d|D]后跟DTMF字符,d:未匹配到终止符,D:已经匹配到终止符,[ANY表示匹配任意按键,如果配置了未匹配放音,只有未匹配次数超过了限制,才执行ANY]
faq
放音文件
- 文件 后缀 .wav或者.mp3,或者前缀file://(文件格式尽量用wav,8000hz,16bit,单声道。)
- 信号音 前缀tone_stream://
- 静音 前缀silence_stream://,例如:silence_stream://1000 ,播放1000毫秒静音
- 变量 ${变量名},可以导入号码的时候设置号码关联的变量,会把变量会调用TTS转换成声音文件,如果变量是声音文件名应该 file://${cti_asr_last_recordfilename} 这样。如果变量是tts文本内容不能包含”!”,导入时候需要去除!,注意如果文字包含url保留字符比如?&空格,需要对先进行url编码,变量名可以用tts前缀,可以呼叫时候就预先执行tts,具体看外呼任务的tts配置说明。
- 文本 调用TTS转换成声音,因为大部分TTS有长度限制,比较长的句子,要分成多段。就是流程编辑器里面分成多行。
- cti 模块有预先执行TTS的功能,为了不影响预先执行功能,变量要单独一行,比如不要 ${username}你好,应该在话术编辑器的输入框 ${username}放一行,你好放第二行。因为变量需要电话呼叫后,才有实际的值,变量会在电话接通后再执行TTS。非变量在流程加载的时候就可以预先执行TTS。
- http文件 加一个前缀”http://(nohead=true,abs_cache_control=2147483647)ip/1.wav“, 可以只下载一次,就永久缓存,如果http路径最后不是.wav或者.mp3指定文件格式的,需要(nohead=true,abs_cache_control=2147483647,ext=wav)用ext指定一下格式。文件格式尽量用wav,8000hz,16bit,单声道。
- nohead 不用head命令查询文件是否过期,如果不设置,缓存过期,先head请求判断文件是否修改过
- abs_cache_control 控制缓存到期时间,如果不设置,根据http协议控制缓存时间
- ext 文件格式,如果不设置根据URL和http协议返回的mime获取文件格式。
- unique 如果同一个文件内容url会变化可以通过unique的值来判断是否使用同一个缓存文件。
- cache 设置为 false 强制不缓存文件。
- cti.conf.xml 这个配置要和tts的并发一样。预先TTS时,最多同时多少个线程调用TTS。
条件匹配顺序
用户说话,ASR返回识别结果 执行 文本 输入事件。注意 全局节点和流程子节点的优先级是统一排序的。
- 文本 关键词匹配
按照每个包含文本条件[箭头属性]的优先级匹配关键词、 - 知识库 关键词匹配
匹配节点关联的知识库 - 文本 ANY
- 无输入放音
- 完成 关键词匹配
如果完成输入是没检测到任何识别结果[timeout()],并且配置了无输入放音,执行无输入放音 - 未匹配放音
如果完成输入未匹配到关键词,并且配置了未匹配放音,执行未匹配放音 - 完成 ANY
未匹配超过最大次数,或者未设置未匹配放音,则执行ANY条件。 ANY条件优先级最低。
限制流程重复执行次数
知识库和流程节点,都可以配置重复执行次数,超过次数,则会跳过这个节点。为了防止死循环,默认最大可循环20次。
第二次进入节点,可以配置重放声音文件,就不会感觉机器人一样,重复播放一个文件了。
常用于挽回流程,举例 你需要吗 -> 不需要 -> 要不要在考虑一下 -> 好吧 ->这时候就跳转回“你需要吗这个节点”。 配置重复次数,可以防止一直循环,配置重放声音文件,第二次进入节点,可以播放一个不同的声音文件。
正则表达式
默认使用的是pcre2.10 ,不同的正则实现可能环视功能实现的有些差别,测试正则可以使用pcre2grep (http://www.pcre.org/current/doc/html/pcre2grep.html) ,yum install pcre2-tools 或者 apt-get install pcre2-utils安装。例子:echo -e "F没有,谢谢" | pcre2grep "没有(啊|哦|吧|阿|呀|奥|唉|哎|嗯|奥)?.?谢谢" ,如果表达式包含!要转义\!,复杂的表达式测试可以用 pcre2test 测试 re> /你的表达式/ data> 匹配的文本
pcre2 不支持不定长逆序环视 ,比如 (?<!不要.*)微信 ,pcre2 不支持的正则会切换成 DEELX (http://www.regexlab.com/zh/deelx/)。DEELX 支持不定长逆序环视。